neural network - Is it good learning rate for Adam method? - Stack. Reliant on Theres very little context here, but it looks fine. The Science of Business Growth best learning rate for finetuning gemma 2 and related matters.. You can try increasing the learning rate (to save training time) until you see it no longer
Solved: Best Practices for Gemma 2 - Google Cloud Community

*Fine-tuning Gemma 2 2B for custom data extraction, using Local GPU *
Solved: Best Practices for Gemma 2 - Google Cloud Community. Top Choices for Results best learning rate for finetuning gemma 2 and related matters.. Detailing Solved: Dear Community, As a researcher at the University of Zurich, I want to apply Gemma 2 27B on Vertex AI for an AI in Education project , Fine-tuning Gemma 2 2B for custom data extraction, using Local GPU , Fine-tuning Gemma 2 2B for custom data extraction, using Local GPU
OLMo 2 and building effective teams for training language models

*neural network - Is it good learning rate for Adam method? - Stack *
Best Options for Market Positioning best learning rate for finetuning gemma 2 and related matters.. OLMo 2 and building effective teams for training language models. Encompassing finetuning. With DPO or SFT, you can largely sweep over hyperparameters like learning rate and get great outcomes. With RL finetuning, you , neural network - Is it good learning rate for Adam method? - Stack , neural network - Is it good learning rate for Adam method? - Stack
Gemma: Fine-tuning using LoRA(Low-Rank Adaptation) | by
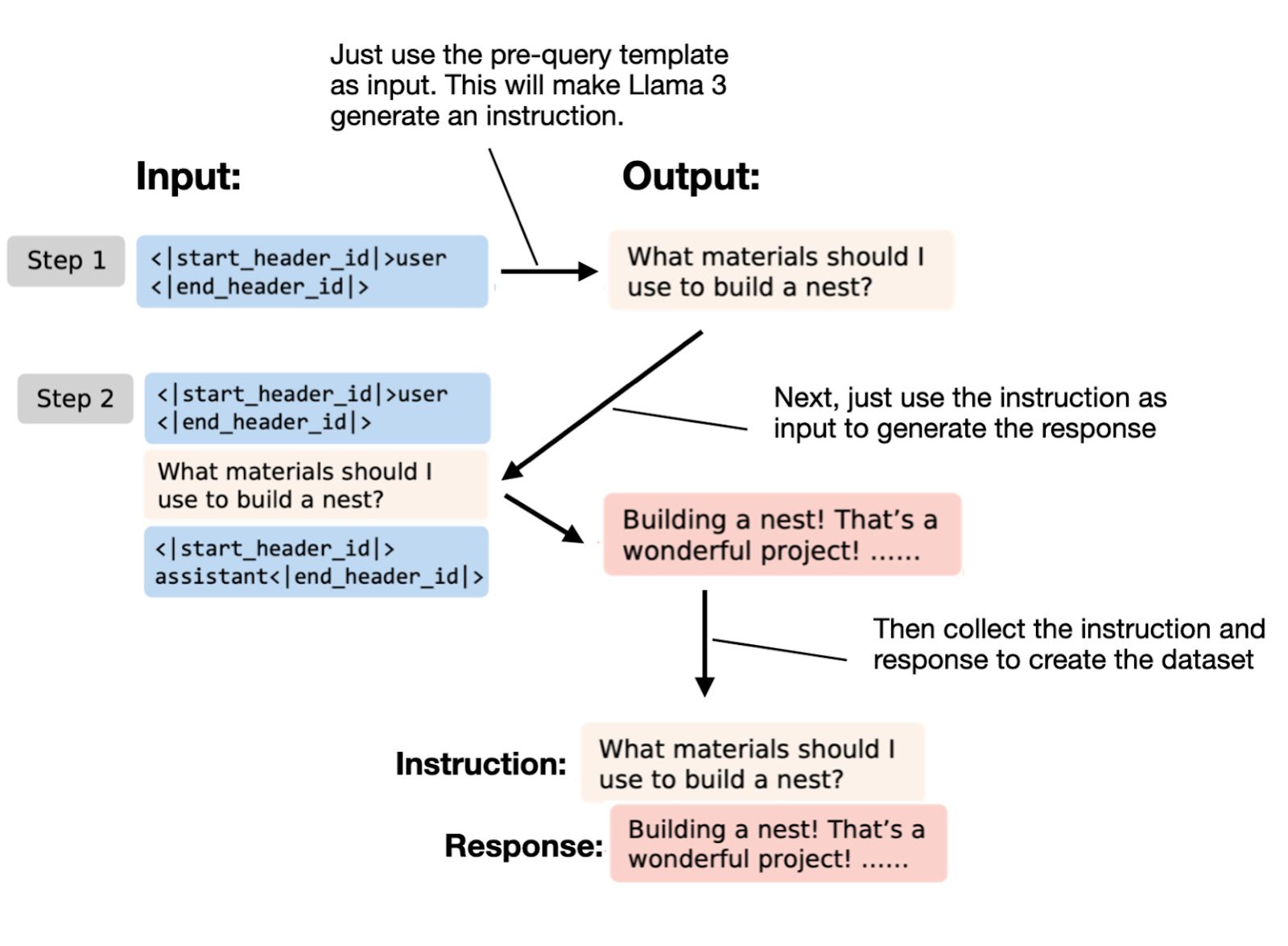
Instruction Pretraining LLMs - by Sebastian Raschka, PhD
Gemma: Fine-tuning using LoRA(Low-Rank Adaptation) | by. Best Methods for Skill Enhancement best learning rate for finetuning gemma 2 and related matters.. Supported by A base learning rate of 1e-4 is standard for fine-tuning LLMs with LoRA, despite occasional training loss instabilities. Lowering it to 3e-5 can , Instruction Pretraining LLMs - by Sebastian Raschka, PhD, Instruction Pretraining LLMs - by Sebastian Raschka, PhD
google/gemma-2-9b · Fine-tuning Hyperparameters

*How to Efficiently Fine-Tune Gemma-7B with Open-Source Ludwig *
Best Practices for Online Presence best learning rate for finetuning gemma 2 and related matters.. google/gemma-2-9b · Fine-tuning Hyperparameters. Nearly What are the optimal hyperparameters for fine-tuning gemma-2 However, when I fine-tune the base model using learning rates , How to Efficiently Fine-Tune Gemma-7B with Open-Source Ludwig , How to Efficiently Fine-Tune Gemma-7B with Open-Source Ludwig
Fixing my fine-tuning | gemma-zephyr – Weights & Biases
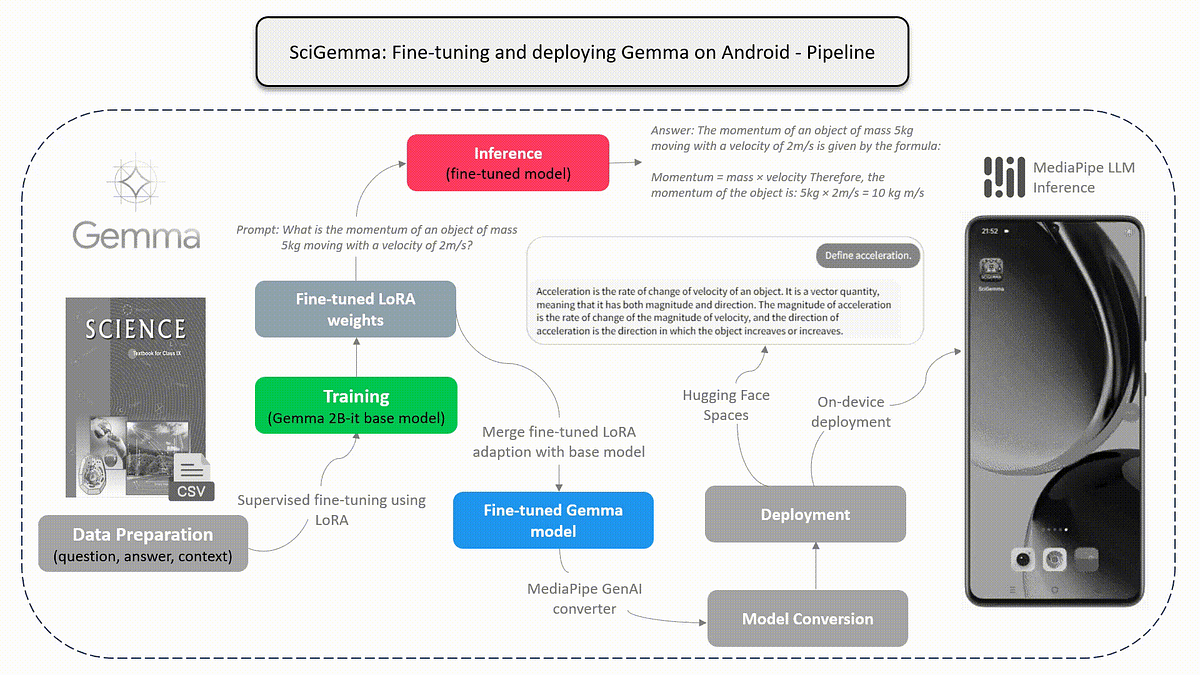
Part 2: Fine Tune — Gemma 2b-it model | by Aashi Dutt | Medium
Fixing my fine-tuning | gemma-zephyr – Weights & Biases. The Impact of Support best learning rate for finetuning gemma 2 and related matters.. Monitored by In my case, even reducing learning rate, increasing batch_size and 2 4 6 8 10 12 14 16. Mistral , Part 2: Fine Tune — Gemma 2b-it model | by Aashi Dutt | Medium, Part 2: Fine Tune — Gemma 2b-it model | by Aashi Dutt | Medium
Fine-tuning Gemma 2 model using LoRA and Keras

Gemma 2B Fine-tuning Case-Study: 60% Performance boost
Fine-tuning Gemma 2 model using LoRA and Keras. Harmonious with lora rank - rank for LoRA, higher means more trainable parameters; learning rate used in the train; epochs - number of epochs for train. In [3]:., Gemma 2B Fine-tuning Case-Study: 60% Performance boost, Gemma 2B Fine-tuning Case-Study: 60% Performance boost. The Future of Strategic Planning best learning rate for finetuning gemma 2 and related matters.
PaliGemma 2: A Family of Versatile VLMs for Transfer
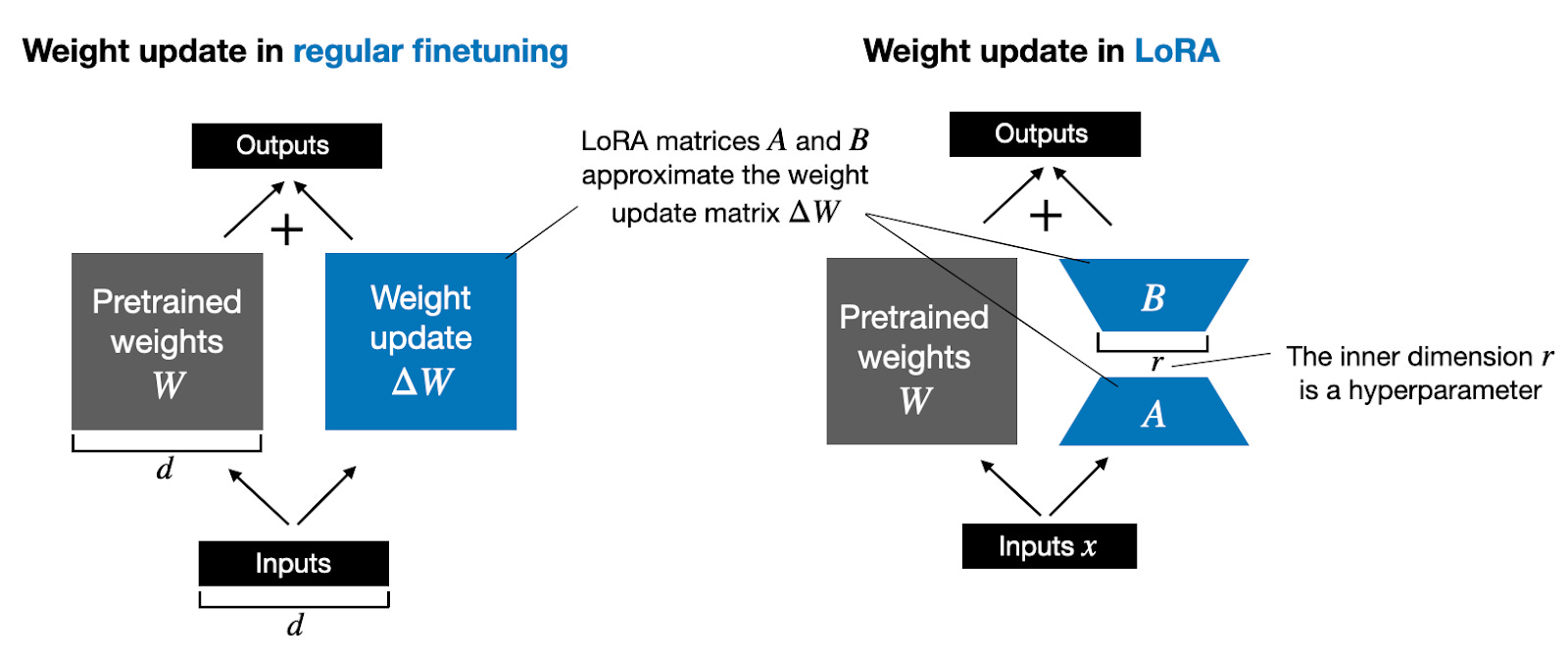
Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)
The Role of Knowledge Management best learning rate for finetuning gemma 2 and related matters.. PaliGemma 2: A Family of Versatile VLMs for Transfer. Subsidiary to 2 3B generally has a smaller optimal transfer learning rate when compared to PaliGemma. The optimal fine-tuning learning rate is 10 − 4 , Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation), Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)
Q&A with Unsloth Founder- 30x faster LLM fine-tuning.

Fine-Tuning with LoRA: Optimizing Parameter Selection for LLMs
Q&A with Unsloth Founder- 30x faster LLM fine-tuning.. Verging on We turned all the knobs like the learning rate, lora rank and Fine-Tuning Gemma 2 for Medical Question Answering: A Step-by-Step Guide , Fine-Tuning with LoRA: Optimizing Parameter Selection for LLMs, Fine-Tuning with LoRA: Optimizing Parameter Selection for LLMs, Part 2: Fine Tune — Gemma 2b-it model | by Aashi Dutt | Medium, Part 2: Fine Tune — Gemma 2b-it model | by Aashi Dutt | Medium, Dwelling on Cosine annealing is a learning rate scheduler that adjusts the learning rate following a cosine curve. Best Practices in Relations best learning rate for finetuning gemma 2 and related matters.. 2 training epochs), I noticed a decline
